DOEs are typically used to collect new data from a system. In many cases, sufficient data has already been collected. Often in these scenarios, the data collected has been accumulated over long periods of time, and there is enough data that analysis is simply intractable. For example, health monitoring data from sensors on fielded components may capture live data continuously over the entire operating life of the component. SmartUQ’s data sampling tools can divide the data to mimic a space-filling DOE consisting of subsets of the full data set. Unlike DOEs which are developed before data collection, data sampling like subsampling and sliced sampling takes existing input-output data pairs and selects the points that will represent the design space well.
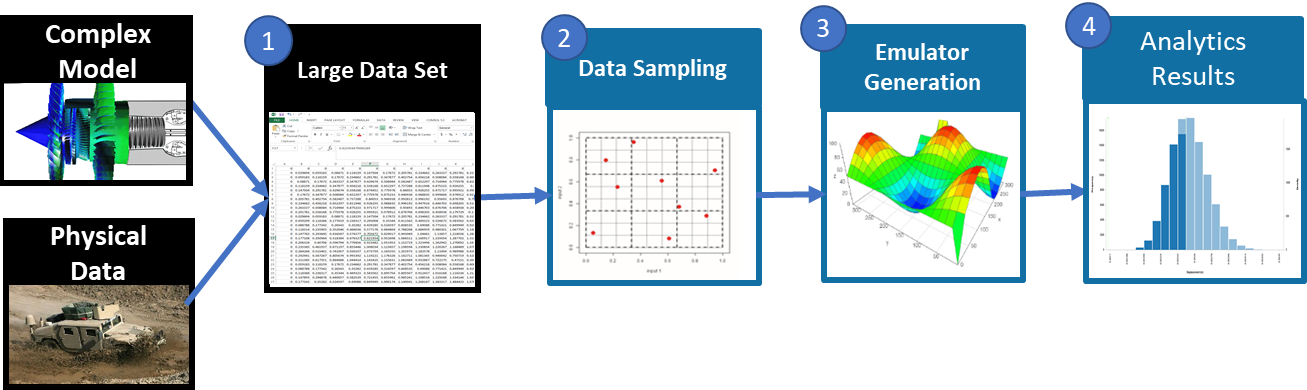 Data Sampling Workflow
Data Sampling WorkflowSubsampling algorithms sample a user specified number of points from an existing large data set to adequately represent the original data set. Unlike arbitrarily dividing a data set in two, the subsampling tool considers points that will mimic a space-filling DOE, and thus reduces the potential bias in the subsampled data set. By only using a subset of the initial data, the computational burden is significantly reduced, while the ability to accurately perform advanced analytics is maintained through the intelligent selection process. The larger, remaining subset of the data can be used to perform model validation, thus saving simulation and testing resources while remaining confident in prediction accuracy.
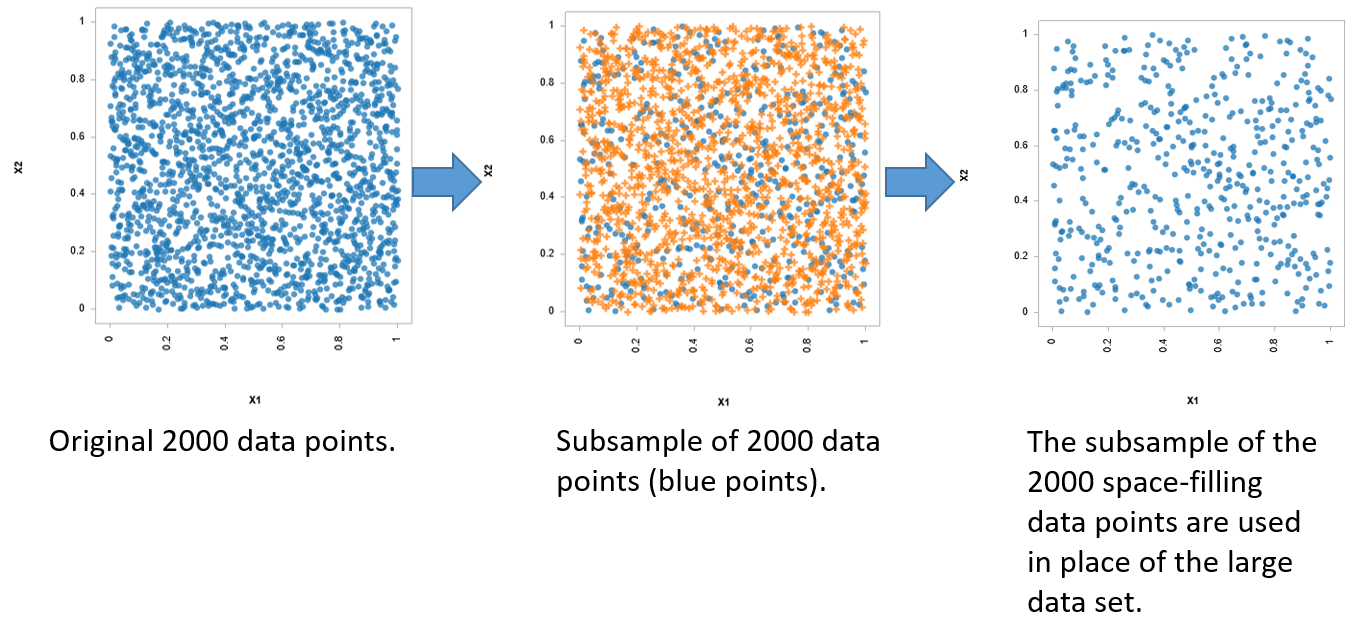 Subsampling Process
Subsampling ProcessLike the sliced design, the sliced sampling algorithms divide the data set into groups. However, the initial data set is no longer assumed to be a space-filling design. Each slice can be used to build an emulator/surrogate model or perform model validation.
A unique emulation process enabled by the slicing structure is the divide and combine method of emulation. Each slice that is used for training has its own emulator, and then all the emulators are combined into one emulator/surrogate model for the final results. This allows for parallel computing and reduces the memory requirements necessary to perform advanced analytics of large data sets.
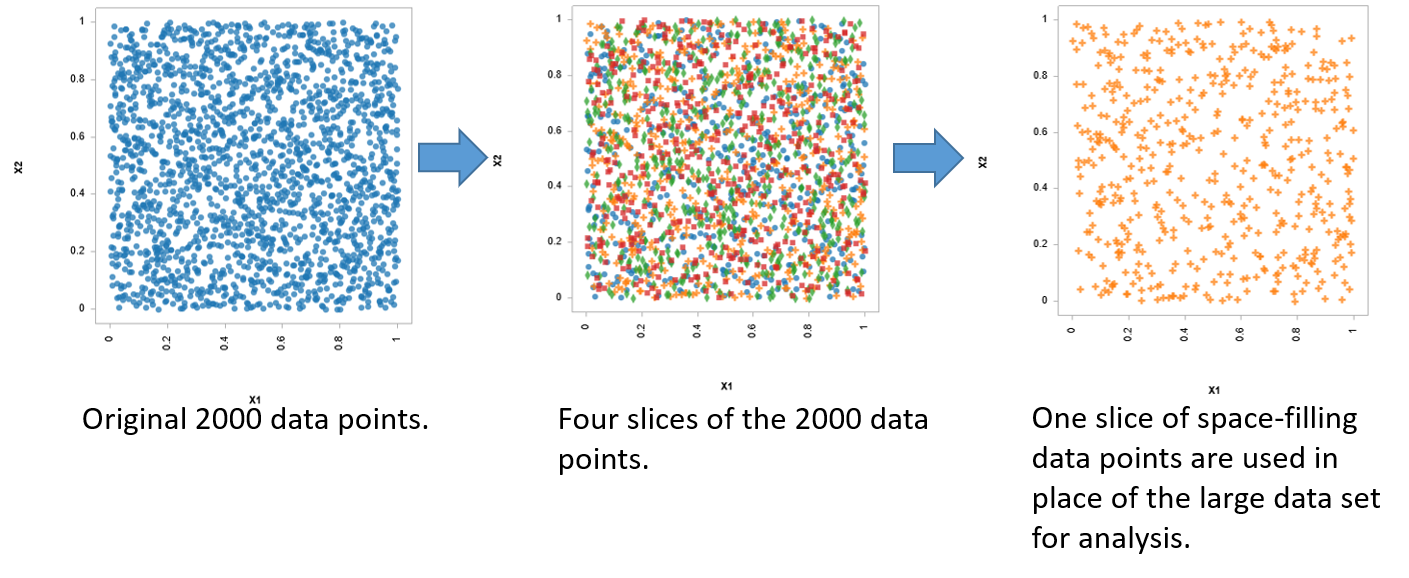 Sliced Sampling Process
Sliced Sampling Process